PuLP to XGBoost Migration
I've been working on corrugate paper scheduling for production for a while, The techniques I use is SAT Solver, CBC Solver, Genetic Algorithms and Heuristic Selection. Because of how complex the rules for planning is I thought that this data is impossible to train a model, but recently I enroll in Data Science course and have a knowledge to determine features and target of data. I use that knowledge immediately, And it came to me that the results I got from my optimization program is the target. So I start working on it right away. I query a year worth of orders from my company database, and feed it to my program. Then I use the output I got, do some feature selection split in to train and test dataset. And use XGBoost with Opuna for hyperparameters optimization with Kfold as cross validation and training for a day.
# Defining the objective function
from sklearn.model_selection import KFold
def objective(trial):
param = {
'max_depth': trial.suggest_int('max_depth', 3, 10),
'learning_rate': trial.suggest_float('learning_rate', 0.01, 0.2),
'n_estimators': trial.suggest_int('n_estimators', 100, 1000),
'subsample': trial.suggest_float('subsample', 0.5, 1.0),
'colsample_bytree': trial.suggest_float('colsample_bytree', 0.5, 1.0),
'min_child_weight': trial.suggest_int('min_child_weight', 1, 10),
'gamma': trial.suggest_float('gamma', 0, 5),
'tree_method': 'hist', # Use 'hist' for faster training, supports GPU
'device': 'cuda', # Specify GPU usage
'objective': 'multi:softmax',
'eval_metric': 'auc'
}
# Initialize lists to store scores for each fold
scores = []
kf = KFold(n_splits=3, shuffle=True, random_state=42)
for train_idx, val_idx in kf.split(X_train.get()):
# Split data into training and validation sets for the current fold
X_train_fold = X_train.get()[train_idx]
y_train_fold = y_train.get()[train_idx]
X_val_fold = X_train.get()[val_idx]
y_val_fold = y_train.get()[val_idx]
# Initialize the model
model = XGBClassifier(**param, early_stopping_rounds=50)
# Fit the model with early stopping
model.fit(
X_train_fold,
y_train_fold,
eval_set=[(X_val_fold, y_val_fold)],
verbose=False
)
# Evaluate on the validation set
score = model.best_score # Get the best AUC score from early stopping
scores.append(score)
# Return the mean score across folds
return np.mean(scores)
def hpo(X_train, y_train):
# Create and run the optimization process with 100 trials
study = optuna.create_study(study_name="xgboost", direction='maximize')
study.optimize(objective, n_trials=100, show_progress_bar=True, n_jobs=-1)
# Retrieve the best parameter values
best_params = study.best_params
return best_params
I also use early-stop features from XGBoost with AUC curve as the evaluation metrics for faster and better model. And since my program have 2 output, roll_width and out. I had to train two models and use both model in concoction. The results is satisfactory as the calculation process is faster by 24.57%.
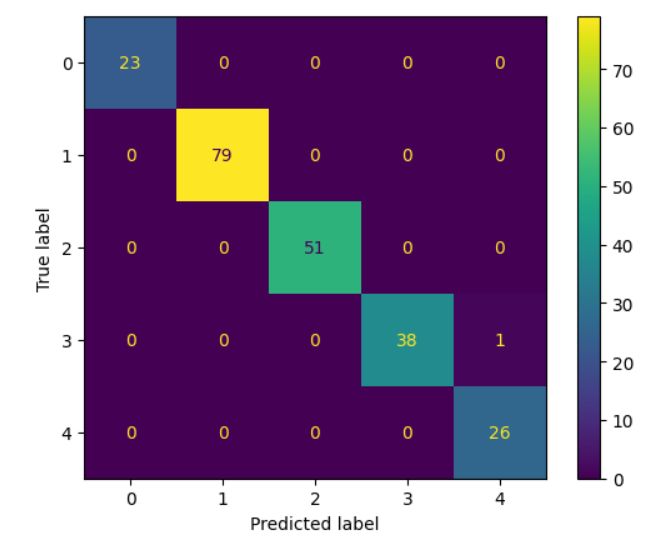
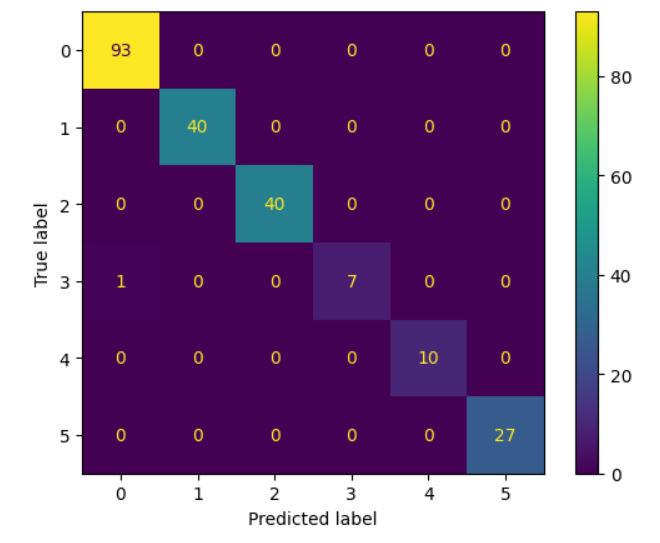
Confusion Matrix from Test set, from roughly around 1,000 of optimized orders.